Search engine bots like Googlebot (Web
Crawling Robot of Google) needs some guidelines on how they have to crawl and
index our blog. We can prevent some non important pages labels pages from
indexing in Google to protect our blog from duplicate content issues. Got
confused? Check out below tutorial which will clear all of your confusions.
What is Robots.txt?
Robots.txt is a text file which contains few
lines of simple code. It is saved on the website or blog’s server which instruct
the web crawlers to how to index and crawl your blog in the search results.
That means you can restrict any web page on your blog from web crawlers so that
it can’t get indexed in search engines like your blog labels page, your demo
page or any other pages that are not as important to get indexed. Always
remember that search crawlers scan the robots.txt file before crawling any web
page.
Each blog hosted on blogger have its default robots.txt file which is something look like this:
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: http://example.blogspot.com/feeds/posts/default?orderby=UPDATED
Explanation
This code is divided into three sections.
Let’s first study each of them after that we will learn how to add custom
robots.txt file in blogspot blogs.
Disallow: /search
That means the links having keyword search just after the domain name will be ignored. See below example which is a link of label page named SEO.
http://www. yourblogname.blogspot.com /search/label/SEO
And if we remove Disallow: /search from the above code then crawlers will access our entire blog to index and crawl all of its content and web pages.
Here Allow: / refers to the Homepage that means web crawlers can crawl and index our blog’s homepage.
Disallow: /yyyy/mm/post-url.html
Here yyyy and mm refers to the publishing year and month of the post respectively. For example if we have published a post in year 2013 in month of March then we have to use below format.
Disallow: /2013/03/post-url.html
To make this task easy, you can simply copy the post URL and remove the blog name from the beginning.
Disallow: /p/page-url.html
Note: This sitemap will only tell the web crawlers about the recent 25 posts. If you want to increase the number of link in your sitemap then replace default sitemap with below one. It will work for first 500 recent posts
Sitemap: http://yourblogname.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
If you have more than 500 published posts in your blog then you can use two sitemaps like below:
Sitemap: http://example.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
Sitemap: http://example.blogspot.com/atom.xml?redirect=false&start-index=500&max-results=1000

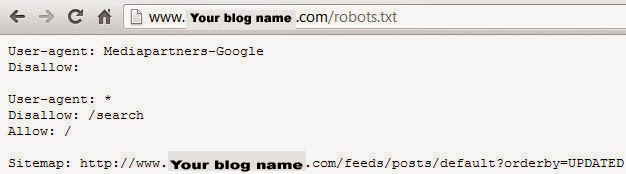
How to Check Your Robots.txt File?
You can check this file on your blog by
adding /robots.txt at
last to your blog URL in the browser. Take a look at the below example for demo.
http://www.bloggertipstricks.com/robots.txt
Once you visit the robots.txt file URL you
will see the entire code which you are using in your custom robots.txt file.
See below image.
Points to Remember
Custom robots.txt is a way for you to instruct the search
engine that you don’t want it to crawl certain pages of your blog (“crawl”
means that crawlers, like Googlebot, go through your content, and index it so
that other people can find it when they search for it). For example, let’s say
there are parts of your blog that have information you would rather not promote,
either for personal reasons or because it doesn’t represent the general theme
of your blog -- this is where you can clarify these restrictions.
However, keep in mind that other sites may have linked to
the pages that you’ve decided to restrict. Further, Google may index your page
if we discover it by following a link from someone else's site. To display it
in search results, Google will need to display a title of some kind and because
we won't have access to any of your page content, we will rely on off-page
content such as anchor text from other sites. (To truly block a URL from being
indexed, you can use meta tags.)
What is Robots.txt?
Robots.txt is a text file which contains few
lines of simple code. It is saved on the website or blog’s server which instruct
the web crawlers to how to index and crawl your blog in the search results.
That means you can restrict any web page on your blog from web crawlers so that
it can’t get indexed in search engines like your blog labels page, your demo
page or any other pages that are not as important to get indexed. Always
remember that search crawlers scan the robots.txt file before crawling any web
page.Each blog hosted on blogger have its default robots.txt file which is something look like this:
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: http://example.blogspot.com/feeds/posts/default?orderby=UPDATED
Explanation
This code is divided into three sections.
Let’s first study each of them after that we will learn how to add custom
robots.txt file in blogspot blogs.
1. User-agent: Mediapartners-Google
This code is for Google Adsense robots which
help them to serve better ads on your blog. Either you are using Google Adsense
on your blog or not simply leave it as it is.- User-agent: *
Disallow: /search
That means the links having keyword search just after the domain name will be ignored. See below example which is a link of label page named SEO.
http://www. yourblogname.blogspot.com /search/label/SEO
And if we remove Disallow: /search from the above code then crawlers will access our entire blog to index and crawl all of its content and web pages.
Here Allow: / refers to the Homepage that means web crawlers can crawl and index our blog’s homepage.
Disallow Particular Post
Now suppose if we want to exclude a particular post from indexing then we can add below lines in the code.Disallow: /yyyy/mm/post-url.html
Here yyyy and mm refers to the publishing year and month of the post respectively. For example if we have published a post in year 2013 in month of March then we have to use below format.
Disallow: /2013/03/post-url.html
To make this task easy, you can simply copy the post URL and remove the blog name from the beginning.
Disallow Particular Page
If we need to disallow a particular page then we can use the same method as above. Simply copy the page URL and remove blog address from it which will something look like this:Disallow: /p/page-url.html
- Sitemap:
http://example.blogspot.com/feeds/posts/default?orderby=UPDATED
Note: This sitemap will only tell the web crawlers about the recent 25 posts. If you want to increase the number of link in your sitemap then replace default sitemap with below one. It will work for first 500 recent posts
Sitemap: http://yourblogname.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
If you have more than 500 published posts in your blog then you can use two sitemaps like below:
Sitemap: http://example.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
Sitemap: http://example.blogspot.com/atom.xml?redirect=false&start-index=500&max-results=1000
Adding Custom Robots.Txt to Blogger
Now the main part of this tutorial is how to add custom robots.txt in blogger. So below are steps to add it.
1. Go to your blogger blog.
2. Navigate to Settings >> Search Preferences ›› Crawlers and indexing ›› Custom robots.txt ›› Edit ›› Yes
3. Now paste your
robots.txt file code in the box.
4. Click on Save Changes
button.
5. You are done!
How to Check Your Robots.txt File?
You can check this file on your blog by
adding /robots.txt at
last to your blog URL in the browser. Take a look at the below example for demo.http://www.bloggertipstricks.com/robots.txt
Points to Remember
- Replace your blog
name with yours in the sitemap section.
- If you’ve more than
500 posts, then simply use this tool to generate the Sitemaps based on your post
count.
- You can also chose
to disallow your privacy and about pages from being indexed. Make sure you
change the URLs with your own permalinks before saving.
No comments:
Post a Comment